Introduction
Editors Note: the following article is targeted at the common Internet user and attempts to avoid technical jargon as much as possible. Its premise is that administrators and programmers already know the shortcomings of Internet security. This article assumes that the reader has covered the previous article for glossary terms and definitions and does not repeat that material.
To begin with, I want to put you in a frame of mind regarding your security. Simply put, you are fortunate if you avoid ever being attacked through means of your computer. You are less fortunate if you have been attacked, but at least were later informed or otherwise discovered it. In that case you go into damage limitation mode and fix whatever problems have arisen.
But what if you don’t realize that you have even been attacked? You cannot ‘fix’ something that you do not know is wrong. Think of someone using your identity to access information to which they should not have access, and creating accounts in places that you do not know exist, and to which you yourself obviously have no access.
Many people are attacked on the Internet but never realize it. On many occasions, when an institution realizes that customers have been compromised, there are allegations that the attack was kept quiet, and damage likewise repaired silently.
In the previous article, we looked over a range of threats that exist for Internet users. In this article, we are going to delve a bit deeper into how these attacks are mounted. The goal is to help you understand how you are being attacked, so that you can correctly assess your level of security as you transact on the Internet.
The Common Login Page: The Common Security Hole
At the core of our identity management problems is the common login page; its vulnerability has fed a whole generation of hackers. The flaw isn’t difficult to understand, either. With usernames and passwords entered either partially or completely, the level of security is weak. Upon successful authentication, the hacker has access to the online facility for the duration of the visit, without hindrance.
This is a key point to understand. A site provides a gateway into its environment, and your username and password details are the key. Once in, there are usually no further identity checks, which means that the only protection to site access – to your email, online banking and so on – is your username and password. In technical speak, we would say that after logging in, session and transaction management are continued until the user logs out, or is otherwise disconnected.
The burning question is why did we (a generation of programmers) ever design and perpetuate a system (the common login box) that we knew to be vulnerable? There are a few reasons: simplicity, complacency and evolution are near the top of the list.
Let’s look at the process of attacking systems that depend on login boxes.
Attacking The Login Page
First of all, finding random sites that use login pages isn’t difficult. A hacker who wants to get a sampling of educational sites with login pages constructed in ASP (Microsoft’s Active Server Pages) would open up a browser with Google and enter the following:
inurl:login filetype:asp inurl:edu
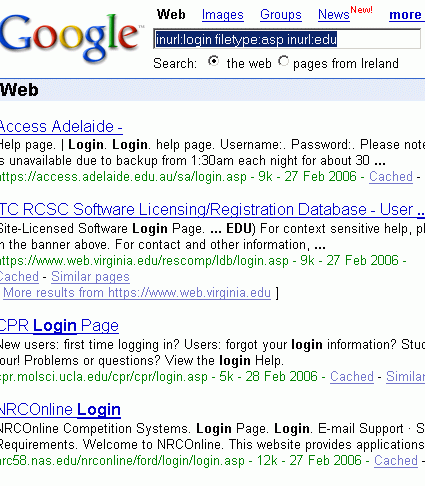
The login page presented is effectively a gateway to an application.
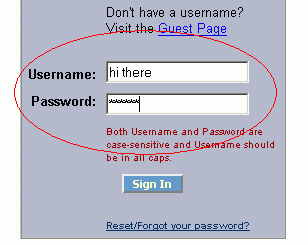
As you enter data in the password box, asterisks appear instead of the characters typed. However, these are just a visual disguise; the password text box actually holds the password as entered. This information is passed to a program or page on the site server where the information is retrieved and tested for validity.
So what can go wrong with that? Try this yourself: Open Google and enter ‘keypress recorder’ in the search box, and see what comes back.

Each executable program mentioned in the search results is capable of sitting on your PC and recording keystrokes as you type them. So, for example, if one were sitting on my machine and recording my every keystroke, it would record a copy of this article as I write it. Some of them are smart and only record keystrokes in response to password prompts. Some of them are even smarter, and do not show up as running programs on the system, even though they are actually functioning. Another technique is to rename the illicit program as something that looks innocuous. For example, would you worry about “winprint.exe” if you came across it in your Windows directory?
Next, go to your Google page and enter ‘screen scraper’. Now what you get is a listing of programs that grab an image of your desktop screen, like when you press the Print Screen button on your keyboard.
Now for the kicker – there are programs out there on the net that will do both of these tasks. Some of them come in the form of Trojan horse and spyware programs. These are downloaded onto your system, usually where you stumble across sites hosting pages where they are embedded – especially porn-related ones – or are perhaps received by email.
If you are infected with such a program, your confidential data will be captured as you enter it. At some time thereafter, your vital information will be appended to an email that reaches the hacker. Alternately, it may be silently ‘piped’ directly to a purpose-built server that harvests such information for later retrieval by the hacker.
You now know that these programs exist, and hopefully can understand that they are capable of recording and passing on vital information. In that light, it isn’t difficult to see why the common logon box is such an easy target. Now think about those sites where you have submitted your credit card details, and where you have agreed to store that data for subsequent and convenient one-click purchasing…
But let’s return to the attack on our login page. When the page is submitted, it passes typically with a POST or GET HTTP Request to its action target. Let us decipher some of this jargon.
HTTP stands for Hyper Text Transfer Protocol, and is the method by which pages of information are formed and transmitted across the Internet. A form can be passed in two ways: through a POST request or a GET request. Suffice to say that both are methods through which data is passed from a browser to a site. Each HTTP request can have a response, so when you submit a search for data from Google, the returning page is an HTTP Response.
Now there are two possible ways to have the data reach its intended target. It can either be encrypted using a mechanism such as Secure Sockets Layer (SSL, using a prefix of HTTPS://) or the information can be sent in the clear (HTTP://).
Either way it can be attacked, but to elaborate on how this can occur, we need to walk through a few concepts first.
Sniffing Packets
A network of computers and peripherals communicate in a very logical and predictable manner defined by a standard called the OSI Model. By adhering to the rules of behavior set out in this model, manufacturers can build multiple products that can seamlessly connect to each other.
Messages and data travel in ‘packets’ that are similar in concept to envelopes in a postal system. Imagine that you have a large letter for your mum, but there are too many pages of text to fit in a single envelope. So you take out as many envelopes as required, number them in order as 1 of 6, 2 of 6 and so forth. You then affix to each an address for your mum, and a return address in the case of non-delivery.
The protocols of the OSI Model are analogous to the work practice of the postman in his/her post office. These are the questions that must be answered:
Question 1 – does the address for mum exist?
Question 2 – what route is required to send a letter there?
Question 3 – can it be delivered – is anyone at home?
Action – send the letters.
Now, because there are six letters, there is no guarantee that the same postal sorter will handle them all, or that they will all arrive together. If mum does not receive all six, she can complain and the postal system will request that you send them again. If she does get them all then she can arrange them in order and read them.
So how do we establish addresses on a network?
Each computer attached to a network typically has three pieces of information that identify it. There is a private unique address associated with the hardware, called a MAC address. There is an Internet Protocol (IP) address that identifies the computer on the network to which it is attached at a given time. And there is the computer name.
As a rule the MAC address remains unchanged, the IP address changes each time the computer is attached to a different address, and any administrative user can change the name of a computer at will.
So why all the addressing?
Think of things this way. Suppose you have a camper van that has a state registration number; this is like a MAC address. You like to drive from camper site to camper site and stay over for a while. Each site has a different street address, and within each site there are numbered bays where you park and plug in. This is like an IP Address. The name is what you choose to call the camper; last year you might have had ‘Bingo Bob’ painted on your van, but this year it’s ‘Elenora’.
For Big Brother to find you, he needs to keep track of your combined registration information and the site and bay in which you are parked. This list, in the techno world, is called the Address Resolution Protocol (ARP) list. Devices connected to a network maintain an up-to-date ARP listing so that the postman doesn’t get lost.
Now we can also have two types of postman: one who likes to meet and chat with everyone and is not discreet, or another that is very efficient and very discreet.
In the former case, the postman knocks at every dwelling in the estate and shows the contents of the letters to anyone who answers the door. In network terms, we would say that our data was being routed on a non-switched network. In the latter case, our discreet postman delivers the letters to your mum only. This form of direct routing occurs on a switched network.
A network that is non-switched is open to very simple form of hacking. If I am sitting on such a network and I am running a program named TCPDUMP, I can operate in “promiscuous mode” to see network packets (our open letters) destined for all PCs on that network. If a user on a PC on the network is logging into a site that does not use SSL, then the username and password will be retrieved by a program such as TCPDUMP, or a more focused cousin named DSNIFF.
ARP Poisoning
Let’s take an example to highlight the issue. The following is a command to TCPDUMP to listen for all traffic destined for Google and to write the information retrieved to a file called goog.txt.
This is like the example of our chatty postman who shows everybody our mail.
![]()
Now open up google and run a query:

If we look at the contents of our goog.txt file we find:

If I’m on a switched network, it means that traffic is routed directly to the intended PC. Since my PC is not in the ‘path’ to listen to switched traffic, I need to do something to get the target computers to communicate with me. I need to confuse the postman into thinking that all the post traveling between houses A and B should actually go through me.
It is the nature of a network that connected machines need to request addressing information from other machines to enable communication. Once this is established, each machine retains an ARP cache that contains an address list of other connected machines that it needs to talk to regularly. This information is acquired on an as need basis; otherwise, every machine on the Internet would have the address of every other machine whether or not it needed to communicate with it.
Say that PC-A is talking to PC-B. Each of these computers has an IP (Internet protocol) address, and a MAC address.
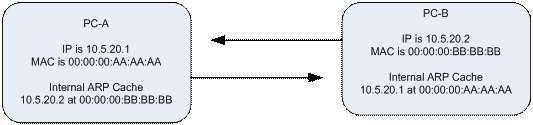
These machines have requested addressing information from each other and updated that data in their respective ARP cache.
To get into the path between these two machines I need to identify the actual information of each, which can be achieved by sending a PING to each machine. At this point, my machine information is as follows:

Now, I generate an ARP reply to each target machine – irrespective of whether their machine actually made an ARP request – causing the cache on each machine to be updated with the information that I send to it.
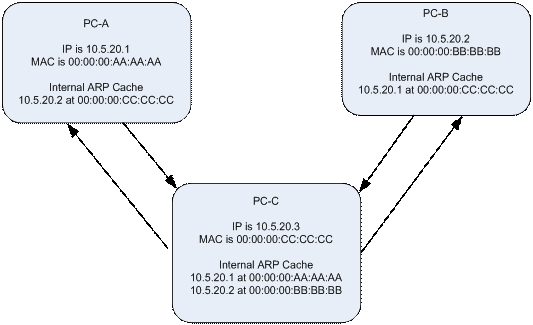
I have “poisoned” the ARP cache in both PC-A and PC-B so that PC-A thinks that I am PC-B, and PC-B thinks that I am PC-A. What we have just described is called ARP Poisoning, and it effectively allows me to be the Man in the Middle (MITM) intercepting all traffic between PC A and PC B.
What’s required for the job? A few simple programs: PING, ARP, NMAP (if you are not sure of the machine that you need to target) and a packet injection program such as NEMESIS or ETTERCAP. An informative resource describing the process for techies can be found here.

The above book also has a very concise description of the process, and the diagrams above were inspired from its content.
Both of these resources require a level of technical knowledge. If you use the techniques without knowing the potential pitfalls, or do so illegally, then you should expect someone to get upset with you when your network segment crashes, or you are reported for unethical activity. You’ve been warned!
Network Admins And Hackers: Using The Same Tools And Methods
The scary thing for the common user is that all of the tools named above are readily available for free download – ping and arp are even standard tools in Windows. And some more automated tools, such as NetScanTools Professional, are available for purchase. To give you a taste of what’s in store if the hacker has that tool, look at the screenshot below.

This toolset permits very incisive targeting by hackers, as there is a good level of inter-tool automation. That is, you can get a list of results from a net scanner, and with a right-click, get a submenu with available options for the results that you have gleaned. Thus you can very quickly and easily check a network and its attached hardware for flaws.
NetScanTools was primarily designed for the network administrator, but there is no escaping the fact that the hacker and administrator share the same toolsets.
Fatal Flaws In The SSL Secured World
I feel that a little more explanation is required about the shortcomings of SSL, especially due to its being portrayed as a panacea for Internet security. The first point to note is that SSL cannot defend you against PC desktop threats such as key loggers and screen scrapers. This is because SSL is a protocol that operates between your browser and the site server to which you are connected. Whatever you do to ‘put’ the information into your browser page is not protected by SSL.
For example, if you are entering your username and password into a login box, as described above, SSL does not secure you against a key logger extracting this username and password and using it to log in on a different machine. SSL doesn’t even come into play until after the username and password have been entered and the browser sends the HTTP request.
SSL comes in different flavors, where the most desirable is the one where both server and client (that’s you) have a certificate loaded on your respective computers. This is not very practical in many cases, because it requires you to have a copy of that certificate on any PC that you may use to connect to the site in question. Many sites do not use that policy, and in that there is a flaw.
In the former scenario, the site’s own server software can authenticate that the SSL ‘tunnel’ starts at the site’s server and terminates on your computer. Without that, we have the possibility of our previously mentioned attack known as the Man in the Middle. You can say that ARP spoofing, as described above, is a form of MITM, but the term is really reserved for situations where security protocols are being used.
MITM is an umbrella term for all kinds of hacking that involve intermediate proxies. The hacker can disrupt packets or flood a server with traffic. He can alter the contents of packets so that client side checks are circumvented, thus exposing server side software to unexpected and possibly unhandled exceptions that cause application or server crashes. This can result in the hacker stealing information and hijacking user sessions to banks and wealth management accounts.
So how can this happen?
Assume that the previous ARP attack is in place, and your associate is connecting to his bank using SSL. Your associate requests the link to his bank, which is received at your computer. You intercept the request and allow it to pass on to the bank. Now the bank’s server initiates an SSL connection destined for your associate. You again intercept the traffic from the bank and terminate the SSL connection on your computer. You then separately initiate your own SSL connection to your associate.
At this point he will receive a notification that there is a difference between the SSL details received, and certified details for the bank.
Of course, you have stopped the real bank’s certificate on your computer. Your associate gets the bank’s actual page, but its details will not match the manufactured certificate that you have forwarded to your associate, so he will get a dialog box on the screen highlighting the anomaly. Most people ignore this prompt, however, and simply click YES to proceed. Big mistake!!!
MITM via Proxy Example
Now your associate does his online banking, and you sit in the middle and watch him do it, get his username and password information, and alter information that he is transacting with. Most importantly, when he decides to log out of the bank, you give him a “bye-bye” message and actually keep open the link between your computer and the bank’s server, so you can keep accessing his account.
This is a serious attack.
There are two products – again freely available – that allow you to demonstrate this behavior: ACHILLES and BURP proxy software.
Above is the BURP user interface.
You will see that the proxy program mimics the MITM receives your browser request for an Internet page.
Upon selecting to forward that page, the result is again returned to the proxy.
As a simple example, set up your proxy in your browser options screen. Now all traffic will travel through your proxy software. In the browser, look for Google. In the search screen type “achilles proxy” and submit.
You will see the HTTP request show up in the proxy.
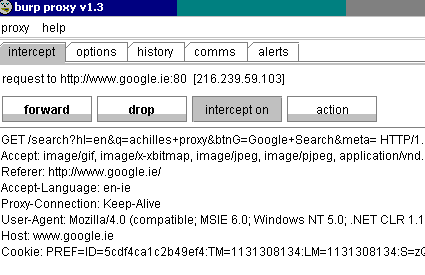
In the intercept tab, look for the word “achilles”.
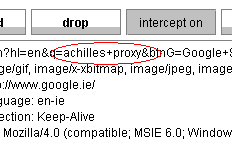
Change that word to “burp”.
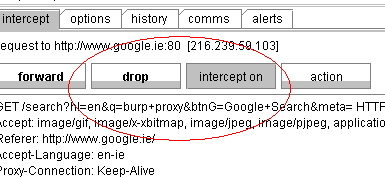
Now, select the forward button and wait to receive the response from Google. Once you receive the response in the proxy, elect to allow it to go through to the browser.
You will notice that although you originally submitted “achilles” in the Google search, you have received back a search based on “burp”.
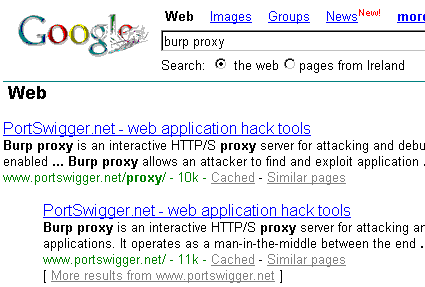
“Ok,” I hear you say. “Sure, why wouldn’t it change, given that you told me to change it in the proxy.” And therein lies the point of the exercise.
You opened a Google page and entered “achilles”. You then intercepted that page in the proxy program and altered the word “achilles” to read “burp”. Google received the changed word and executed and returned data based on that search.
If someone were doing this for real, you would have no control over what happened to your browser request page after you had submitted it. And it wouldn’t be an innocuous site like Google to which the information was being sent. If this were your bank page, and you elected to pay your credit card bill of $1000, and a MITM intercepted it and changed it to $1, you would be a bit miffed. It doesn’t take much imagination to think of even worse possible scenarios.
So, in the future, when you see the padlock icon in the browser, don’t let your feeling of security get the better of you. And if you have been prompted with any message that implies that something is wrong, pay attention to it!
Incidentally, SSL can be configured to resist MITM attacks. We’ll come back to this in a future article.
In Conclusion
There are some in the security business who advocate that strong passwords will solve most of the difficulties associated with identity management and authenticating users. But all of the previously mentioned attacks will break any non-ciphered password entered. Others advocate using Two Factor Authentication (covered next in the series), but even that is susceptible to the MITM attack.
With this information in hand, take a fresh and critical look at that login page when you next use it. You will be able to make your own mind up about the level of security afforded to you by your site administrator. This is particularly true in cases where you are parting with sensitive information.
So, you may ask, what can I do? Actually, not all that much. You can be wary of certificates, look out for malicious software on your computer, and so on. In the end, however, it is up to the security industry to create solutions that go to the roots of these problems, and systems administrators to implement those solutions and get ordinary users to employ them. There are many initiatives in progress to protect against these attacks, but not everyone has access to them yet. In the meantime, beware!
Pat McKenna is a security consultant and CTO with 2SA Plus, a company specializing in Two Factor Authentication and matters of Identity Management. He is 45 and has been in the IT business for 15 years, during which he has held many positions, including company director. Prior to a career in IT, he worked in the security & intelligence field. He is proficient with many computer languages, old and new, and has trained hundreds of programmers. His hobbies are chess and penetration testing (aka ethical hacking).