Network Attached Storage (NAS) is becoming more common in many homes and small offices. This is not surprising, because it is very convenient to have a single big data store with some protection against disk failure provided by RAID.
Sooner or later, however, you may run out of storage room. Storage capacity in today’s NASes can usually be expanded in two ways:
- Backing up the NAS, shutting it down, replacing all drives with larger ones and copying back the original data
- Replacing drives one-by-one with larger ones and letting the RAID volume rebuild between each disk swap.
I’ll call the latter process a rolling upgrade. While doing a rolling upgrade is more convenient, I will show there are consequences that should be kept in mind.
Up to around 2008, NASes used only md-RAID to combine NAS disks into RAIDs. In these NASes, it was impractical to have disks of different sizes because volume capacity was limited by the smallest array member disk due to md-RAID limitations. Even if you replaced disks with larger ones, you would not get more capacity because the excess disk space would just remain unused.
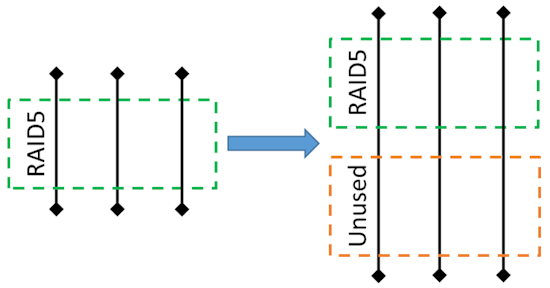
Fig. 1. Replacing disks in a NAS that does not support expansion.
Complex partitioning schemes used in modern NASes allow disks of different size in one array. These schemes are usually based on a combination of LVM (Logical Volume Manager) and md-RAID (standard Linux software RAID format). Examples are NETGEAR’s X-RAID2 (Pre-ReadyNAS OS 6.2) and Synology’s Hybrid RAID.
Let’s imagine you buy a RAID NAS consisting of three disks, 1 TB each, and set up a RAID 5 volume. In this case, you get the following scheme where you have 2 TB for user data and 1 TB for redundancy.
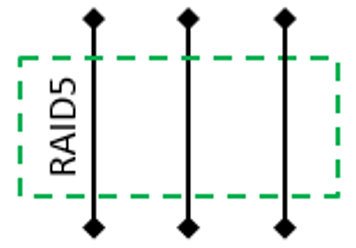
Fig 2. Initial RAID 5 layout over identical physical disks before upgrade.
I’m showing only large data partitions in the diagram. Small partitions storing NAS firmware are omitted.
Some time later you decide to expand the array by replacing the original 1 TB disks with 2 TB disks. After the first replacement and subsequent volume rebuild, you still have a RAID 5 volume with the excess space on the 2 TB disk remaining unused:
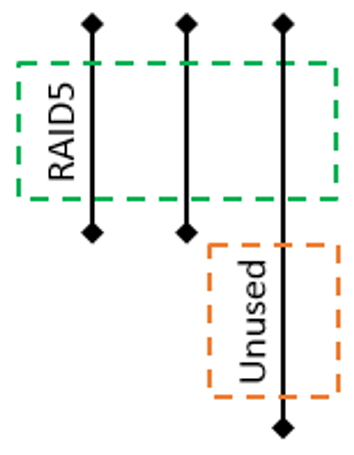
Fig 3. RAID layout after the first disk replacement
After the second disk replacement and volume rebuild, we now get two different RAIDs.
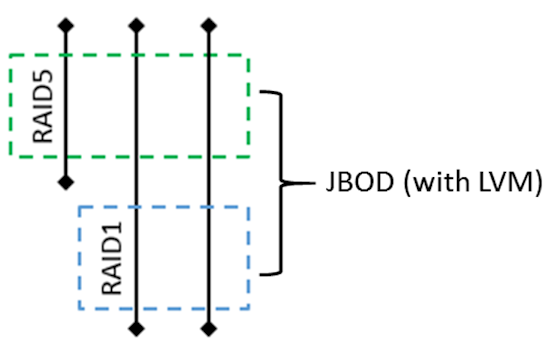
Fig 4. RAID layout after the second disk replacement.
A RAID 5 of three disks still provides only 2 TB available disk space. A RAID 1 created on the excess disk space available on the two larger disks gives you 1 TB of added disk space, while another 1 TB is used for redundancy. RAID 5 and RAID 1 arrays are in turn combined into a JBOD with the help of LVM.
However, all these details are hidden from the user, who just sees 1 TB of extra disk space in addition to the original 2 TB. It is important to note that the array at this point uses mixed RAID levels. Part of the data is stored on the RAID 5, and the other part on the RAID 1. Since either of these survives a single disk failure, there is no degradation as far as fault tolerance is concerned.
Finally, replacing the third drive yields the following:
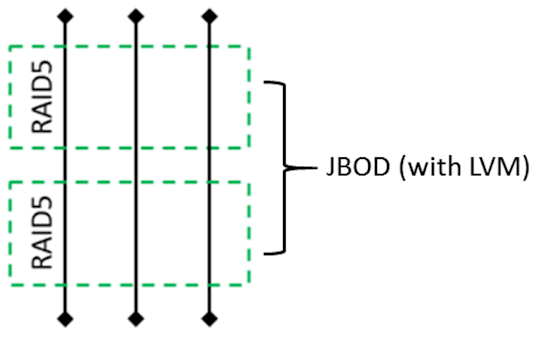
Fig 5. Final RAID layout after a rolling upgrade.
You now have finally increased NAS capacity from 2 TB to 4 TB (one disk’s capacity is still used for redundancy). But you don’t really have the single RAID 5 volume shown in your NAS disk manager, you have two separate RAID5 arrays combined into a JBOD.
More complex combinations, involving multiple upgrades and / or disks of unequal capacity, result in even more complex volume configurations. As long as everything works, there is nothing wrong with using rolling upgrades. But in case of NAS failure beyond RAID 5’s single drive fault tolerance, i.e. software bug, hardware failure or anything else causing superblock corruption, DIY recovery of such a configuration is almost impossible. Some data recovery services won’t even accept such a case. And those that do may not guarantee successful recovery.
NETGEAR’s ReadyNAS OS 6.2 changed filesystems from EXT4 to BTRFS. This has the advantage of eliminating LVM, which is the most complex part of the md + partitioning + LVM + EXT4 combination used by its competitors. But NETGEAR’s new OS still relies on md when a disk fails and that’s the main point of failure when dealing with a corrupt rolling upgraded volume. There are still two md arrays with different disk order (depending on replacement order) and, most importantly, the precise boundary between arrays is unknown.
NETGEAR says the multiple md arrays can be avoided by disabling X-RAID temporarily (switching to standard RAID aka "Flex-RAID"), adding new (larger) drives one at a time with volume rebuild between each drive swap, then toggling X-RAID back on. X-RAID will then use all drives in one expansion operation that doesn’t require multiple partitions or MD-RAID groups.
To sum up, I am not trying to dissuade you from doing a rolling upgrade. Just keep in mind that with every rolling upgrade, your chances of recovering a corrupted volume may decrease.
Elena Pakhomova is the co-founder of ReclaiMe Data Recovery. This article is based in part on the ReclaiMe tutorial series at www.data.recovery.training.